Data Science at EnergyWise – Part 1

Data Science at EnergyWise
This is a series of 2 articles that dives into data science discipline at EnergyWise:
- 1st article (present one) is about the data-driven philosophy we have in our company, and how work is organized around it
- 2nd article depicts main problems we try to solve by applying data science, and how it is technically designed.
Investing in data
Designing air quality monitors has a lot to do with data: real-time air quality readings are useful to our users in many cases: they can act directly whenever air quality degrades, or setup home automations using Nest, Ecobee, IFTTT or other integrations we developed to automate ventilation systems based on air quality.
But some key elements are missing: as a user, how do I know what the main pollution source is in my home? What can I do about it and when did air quality really start to degrade? Moreover, how efficient is the solution I have just put in place? These are some of the questions that require long term analysis and accurate responses.
There are many other areas where data analysis shines and where it can add value. For example how is air quality affected by common external factors (like outdoor particles, NOx, weather, …), what habits a user has is able to bring the best solution or worsen air quality. One may also be interested in knowing how sensors behave and age in varying conditions: some sensors require calibration at different phases in their life, and some others react to external factors.
This article is about how the data science discipline can help us in creating value for our users and how central the discipline is in the development of our products.
Our gems
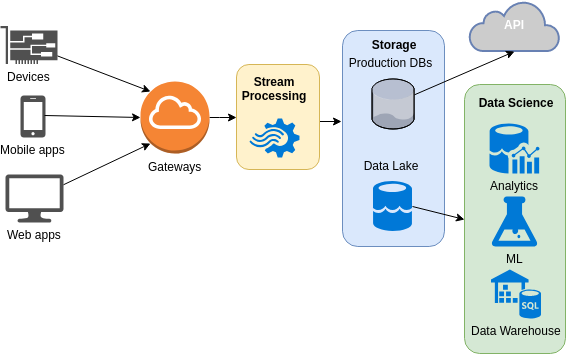
EnergyWise data sources
There are multiple data streams ingested by our data platform, the 3 main being the following:
- Device’s data coming from our units in the wild. Depending on the product, there can be from 5 to 20 sensors continuously sent by devices, to which we can add aggregations, error codes and unprocessed values also computed by the device itself. Some devices (like air purifiers) send commands and status about other components (like change of fan speed)
- User’s data coming from apps and dashboards. Think user profile, user interactions …
- Outdoor data integrated from external providers. It includes sources of outdoor pollution and weather.
Additional data coming from different sources are also used on a day to day basis. Some of them have dedicated ingestion pipelines (e.g. server logs from operations), some others are ephemeral (e.g. an archive file containing pollen data for a specific area in order to check a correlation).
Compared to other IoT companies, we have kind of an advantage in that we design air quality monitors and air purifiers, but we also develop embedded software for them which sends data to our own services in the cloud, and we are able to update their embedded software (firmware) at anytime if needed. The whole data acquisition process is in our hands. That means that if a team member needs explanations about some new sensor value or if a next generation device needs to send metrics differently, we are able to quickly refer to the person sitting next us.
As an engineering company with data-driven processes at its heart, data quality is a matter of high importance. Data quality is never overlooked, trade-offs are often in favor of preserving quality. As a result, our data streams and data lake are well documented, pipelines are written in a way that fosters high quality data sources and sinks, and everyone in the company cares about it.
Our goals
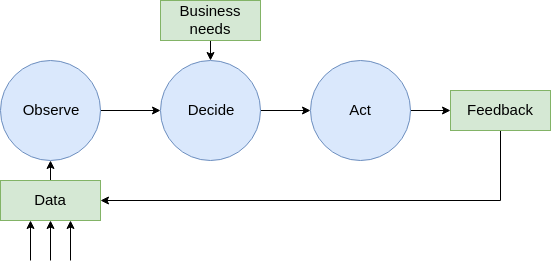
Simplified data-driven decision process
Data Science team “customers” are both internal (business, but also tech teams who wants to find ways of improving reliability of our sensors, services or infrastructure), and external (our users, who are our main concern, and external partners, who want to keep track of their unit fleets with various metrics – manufacturing line metrics, sensors drift over long period of time, …).
Data is central in IoT. This makes an important difference when it comes to our day-to-day duties: extracting value out of data matters because products and features are built on top of it. For our CEO, hardware engineers, project managers or sales people, it’s a source of truth for designing products, improving user experience or advertising about our expertise. This isn’t like we had sit on a huge pile of undocumented data sources for years then realized this could be of interest: we cared from day 1. As a consequence, data science is one of the hottest topic in the company, and we work with enlightened people who knows what to expect.
Data driven decisions
Our company sells primarily technology, and services around it. Data is key in the decision process in a wide variety of fields like new sensors assessment and selection, or new features development in mobile and web applications.
Our decision process includes answering data questions early, with dedicated communication channels, like our internal Slack #data channel where questions are raised and where discussion begins.
Analytics & ML products (user-facing features or not)
We have around 20+ projects where data science is involved, and often key component of the project. It ranges from in-app analytics to hardware failure detection. Not all projects require the same set of skills or data science assets, and not all involve machine learning. But machine learning is ranking often high in our projects options list as complexity is kicking in and amount of data to deal with gets bigger.
Indoor Air Quality expertise
Air quality is a complex topic and there are tons of things we learn every time we dig into our data sources. We try to build a knowledge database from that so we can make our users benefit from it. It also applies to hardware components we select and ship in our products – especially sensors – as there are lot of different ones, with different behaviours and capabilities, aging mechanism, etc. It’s a great source of information for building new products.
Projects organization
We’re a small shop, so it’s crucial for people working with us to go beyond traditional role boundaries. Regarding data science, scientist is involved in business requirements gathering, data engineering (defining what data, at what frequency, …), productionizing models (e.g. embedding model in a real time pipeline), creating visualizations and communicating results. It’s an intense mission, but it comes with the reward of mastering the whole data life cycle.
This is also true for business people: while technical people may not be always available to answer data-related questions, it’s better if they can look by themselves. This requires well organized and documented datasets, as well as simplified access to data: saved SQL queries, table views, charts templates… So this can turn into a real efficient process. This is called data as a service and it requires more than some tools or a dashboarding solution: making data available to others inside the company is also about communication.
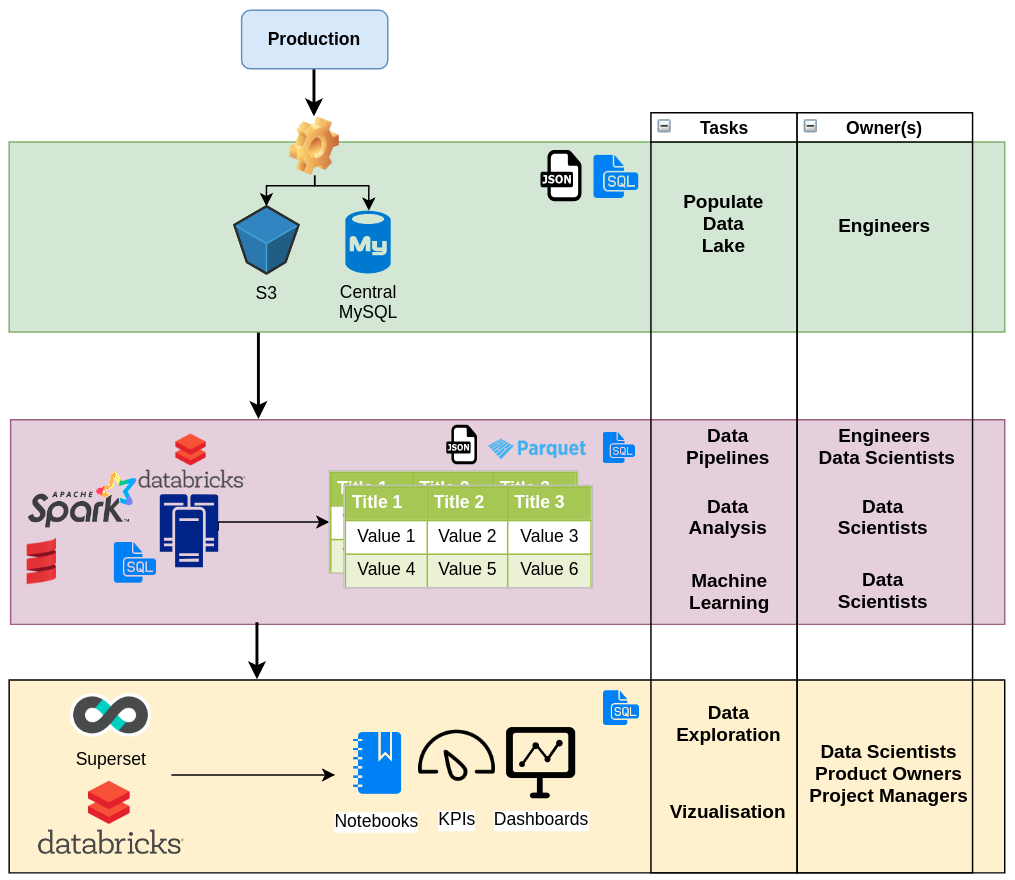
Work-flow and ownership
The team.
Our backend team is composed of seasoned developers, who like to work on complex problems and huge datasets. With data science field gaining maturity, and ecosystem evolving rapidly towards more developer-friendly frameworks, it’s now doable for us to tackle complex projects. The most important thing about that is we’re intimate with the whole data process, which removes the traditional barriers of moving a project from concept phase towards product. With the number of projects grows our expertise in analytics and ML.
Conclusion
In this 1st article we have exposed EnergyWise data science process and vision, from a functional perspective. Next article dives into more technical things, like data pipelines design and types of data-related tasks we’re tackling.